Infrastructure · May 2026
AI Datacenters Were Built for GPUs.
What Happens When You Remove the GPUs?
For the past few decades, building a datacenter has been a well-understood, predictable exercise in utility engineering. You provisioned compute servers, attached storage arrays, and built a network to stitch them together. The objective was straightforward: maximize utilization while minimizing cost.
The dominant traffic pattern was fundamentally north-south (clients sending requests to servers, and servers responding with database queries) and a few east-west traffic from servers to storage. The networks were built to handle bursty traffic, and if a packet dropped, standard TCP/IP would retransmit it. In web hosting or cloud services, a minor delay meant an image loaded slightly slower or a request completed a few milliseconds later. It was tolerable.
AI training changed that model completely. The network is no longer infrastructure. It directly determines accelerator utilization.
The AI shift
In modern AI clusters, the network is no longer just infrastructure sitting beneath compute. It is not simply transporting data between machines but determines accelerator utilization.
If you are training large models under the deep learning paradigm, you aren't dealing with independent servers. It is rather a massive, distributed supercomputer where thousands of GPUs must continuously swap parameters. The dominant traffic pattern shifts completely to east-west traffic (server-to-server, GPU-to-GPU and rack-to-rack) communication inside the cluster. In contrast to localized, bursty spikes, AI workloads execute communication patterns like all-to-all and all-reduce.
Instead of millions of small independent flows, the network must carry a small number of extremely large elephant flows. During gradient synchronization phases, thousands of GPUs may simultaneously exchange data across the fabric, creating severe network incast and rapidly saturating switch buffers.
This shift broke many of the assumptions standard networking was built on. When a modern accelerator can consume and generate data at 800 Gb/s, the critical metric flips from average latency to Job Completion Time (JCT) and tail latency.
In deep learning training, workloads execute in tightly synchronized steps. Meaning the entire workload progresses at the speed of the slowest participant.
One delayed packet can stall thousands of GPUs.
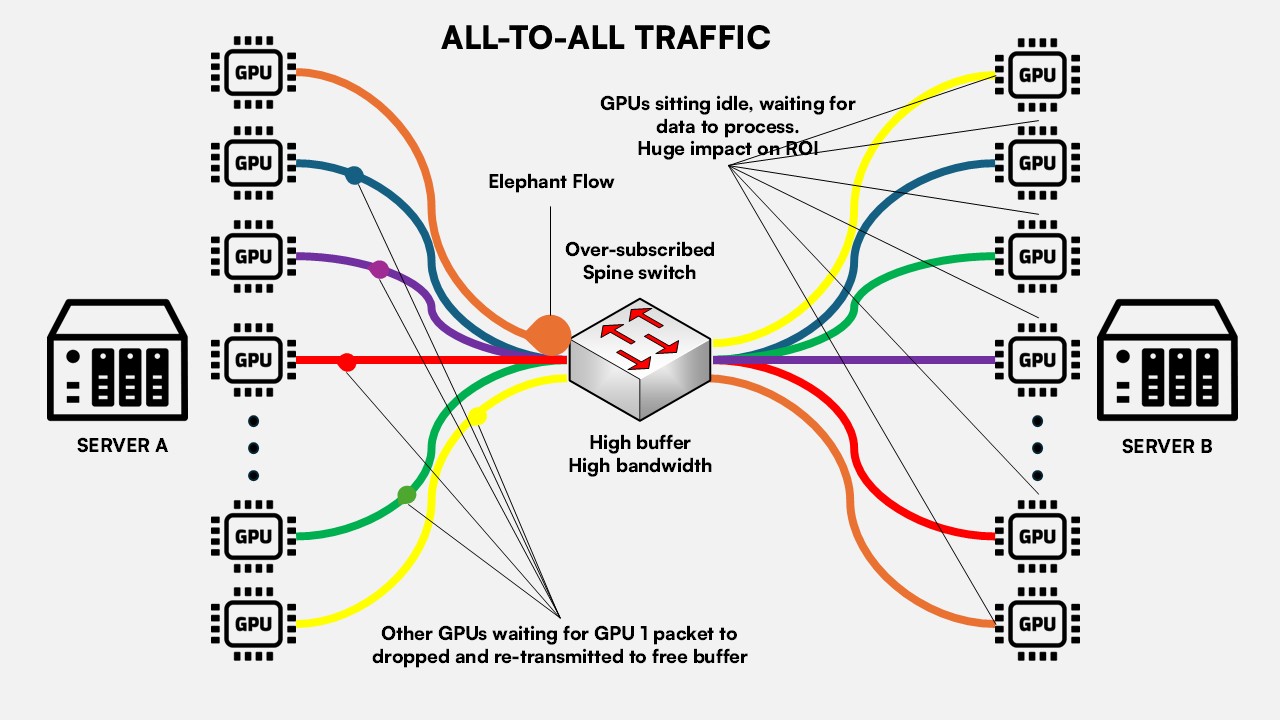 Figure 1: Synchronized elephant flows causing switch buffer saturation.
Figure 1: Synchronized elephant flows causing switch buffer saturation.
Solving packet loss created a new problem: head-of-line blocking
The sensitivity to packet delay is amplified by the transport layer AI clusters rely on. Modern distributed training heavily uses RDMA through RoCEv2 (RDMA over Converged Ethernet), allowing GPUs to bypass the CPU and operating system entirely for low-latency direct memory access across GPUs. But while RoCEv2 dramatically reduces overhead, it is also highly sensitive to packet loss. A single dropped packet can trigger retransmissions, timeout cascades, and synchronization delays across the cluster.
To achieve loss tolerance, standard RoCEv2 networks rely on Priority Flow Control (PFC). Conceptually, PFC acts like a pause mechanism: when switch buffers begin filling, the switch instructs upstream devices to temporarily stop transmitting traffic.
But this creates another problem: head-of-line blocking.
PFC solves packet loss by propagating congestion backward through the network. Under sustained load, this creates head-of-line blocking, where unrelated traffic becomes trapped behind congested flows. Congestion spreads across the fabric, queue depths increase, and entire sections of the network can become effectively synchronized around the slowest traffic path.
In distributed training environments, this is expensive. The compute cluster cannot advance until every synchronization operation completes. GPUs remain idle while waiting for retransmitted packets or congested flows to clear.
The incumbent answer: InfiniBand and Rail Optimization
To maximize GPU utilization, the industry's immediate answer was to throw hardware at the problem. NVIDIA capitalized on this by dominating the AI datacenter landscape with InfiniBand — a native lossless fabric designed specifically for high-throughput, low-latency clustering. Unlike conventional Ethernet deployments, InfiniBand was built around deterministic transport behavior, hardware congestion management, adaptive routing, and tightly controlled latency characteristics.
To scale these clusters, engineering teams have had to navigate three distinct network vectors:
- Scale Up: Maximizing the high-speed interconnectivity within a single chassis or node (e.g., stitching 8 GPUs together using NVLink).
- Scale Out: Expanding horizontally by connecting these multi-GPU nodes across an entire data hall using a dedicated backend network fabric.
- Scale Across / DCI (Datacenter Interconnect): Linking entire clusters together when physical power and cooling limits prevent a single site from expanding further.
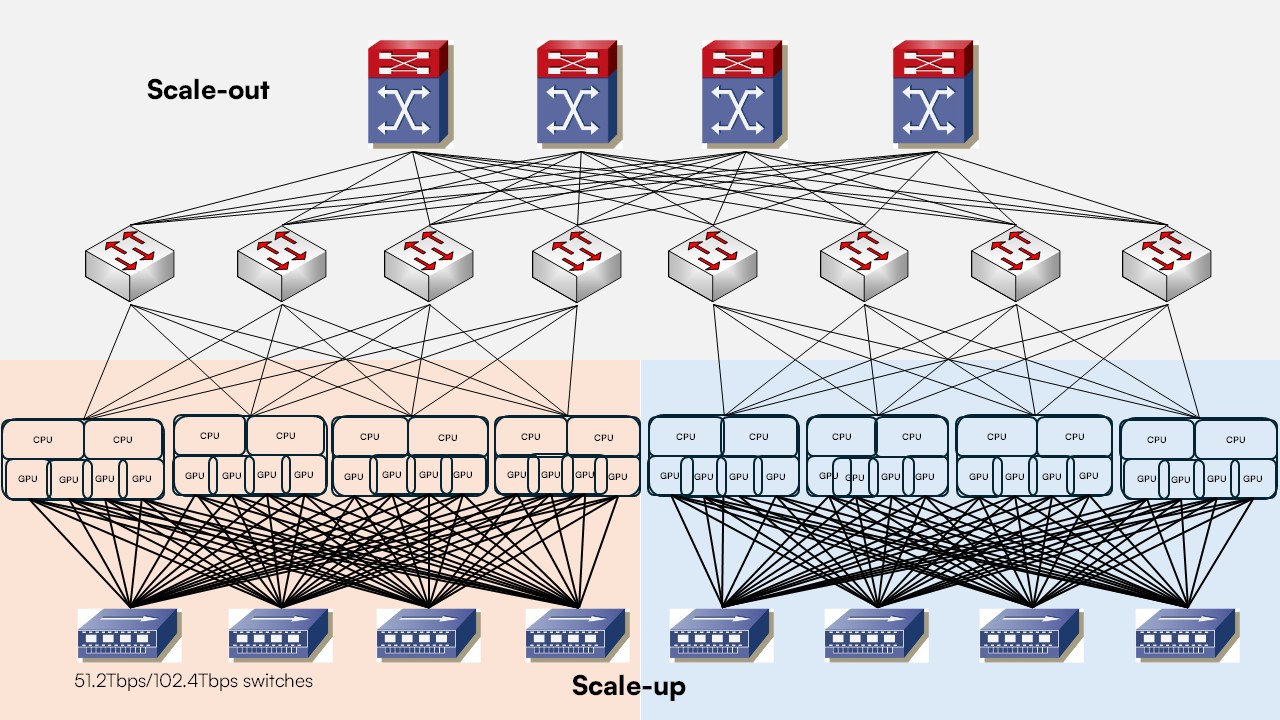 Figure 1: Scale-up is for memory & Scale-out is for compute
Figure 1: Scale-up is for memory & Scale-out is for compute
We're entering the end of scale-up as NVIDIA now delivers complete racks with every GPU accessing every other GPU's memory through NVLink (on the same chassis) and NVSwitch (in the same rack). The next years will consist of focusing on using Connect-X NICs for connecting different racks.
To manage the massive scale-out fabric, modern topologies are rigidly designed to be rail-optimized. In an 8-GPU node configuration, each of the 8 GPUs is mapped to a dedicated, independent network interface card (NIC). The network fabric is split into 8 parallel, isolated physical switch planes. GPU position 1 across every server communicates exclusively through rail 1, GPU position 2 through rail 2, and so on.
This isolation reduces congestion interactions and improves failure containment. If one network plane experiences degradation, the cluster loses only a fraction of aggregate bandwidth rather than stalling the entire distributed workload.
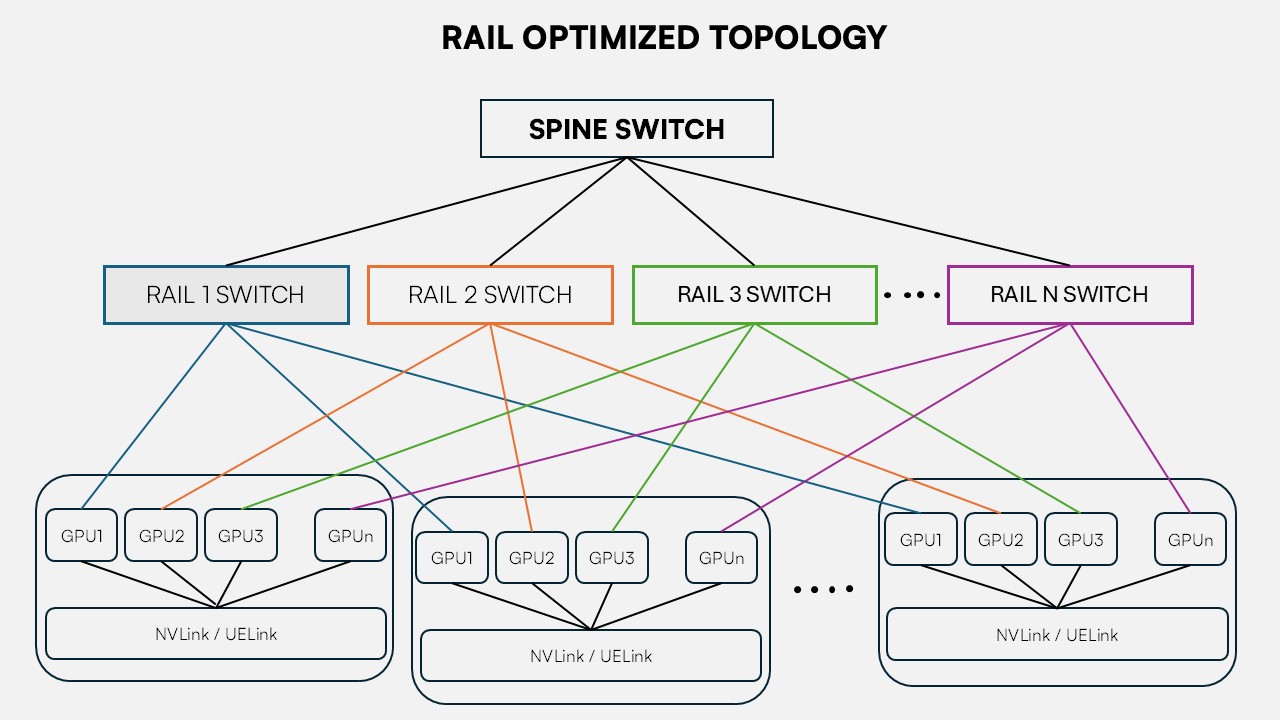 Figure 1: 2-Tier Rail-optimized topology.
Figure 1: 2-Tier Rail-optimized topology.
ECMP & elephant flows
Rail-optimized architectures exposed another weakness in conventional networking.
Traditional routing protocols cannot handle this architecture efficiently. Standard IP networks rely on ECMP (Equal-Cost Multi-Path) to distribute traffic across paths. ECMP works by hashing the packet's header (static 5-tuple) to assign a flow to a specific path. In web applications this works extremely well because traffic consists of large numbers of relatively small independent flows.
AI traffic behaves differently because distributed training creates a small number of massive elephant flows. ECMP hashing inevitably creates collisions where multiple large flows become pinned to the same physical links while alternative paths remain underutilized. The result is buffer pressure, more congestion, packet drops and tail latency spikes.
To counter this, modern AI switches utilize DLB (Dynamic Load Balancing) and packet-spraying mechanisms. Instead of routing by flow, the hardware breaks elephant flows apart, and schedules traffic dynamically based on real-time port congestion.
This is the environment that led to the emergence of the Ultra Ethernet Consortium.
The Ultra Ethernet Consortium
InfiniBand works, but it is expensive, closed, and forces vendor lock-in. The broader ecosystem's response is the Ultra Ethernet Consortium (UEC): a comprehensive re-architecture of Ethernet designed specifically to challenge InfiniBand on AI workloads, without giving up Ethernet's vast ecosystem and economies of scale.
Instead of relying on crude, flow-level pause mechanisms like PFC, Ultra Ethernet moves the intelligence to the transport layer. It natively introduces Packet Spraying: rather than forcing an entire elephant flow down a single hashed path via ECMP, UEC switches chop the flow down to individual packets and scatter them across every available link in the fabric simultaneously.
This naturally introduces out-of-order packet delivery, so Ultra Ethernet incorporates hardware-level packet reordering at the NIC layer. It also pushes toward mechanisms like Virtual Output Queueing (VOQ), where packets are buffered based on final destination rather than competing broadly for shared output queues. The goal is to minimize head-of-line blocking, reduce congestion propagation, improve load balancing, and stabilize tail latency under synchronized east-west traffic.
GPU-free AI Datacenters
In many ways, both InfiniBand and Ultra Ethernet are attempting to solve the same fundamental problem: the communication overhead imposed by large-scale distributed deep learning.
Modern AI systems distribute enormous parameter spaces across thousands of independent accelerators. Keeping those systems synchronized requires sophisticated networking architectures, specialized transport behavior, and large power budgets dedicated purely to coordination overhead.
The complexity of modern AI infrastructure is not accidental. It is downstream of the computational assumptions the models themselves impose.
This is where we believe a different architectural direction becomes interesting. At Almartis, our work explores associative memory systems built around explicit, addressable, and deterministic memory structures rather than large-scale distributed tensor optimization. Instead of relying primarily on statistical approximation across billions of continuously synchronized parameters, the architecture emphasizes structured retrieval and compositional memory operations.
That changes the infrastructure profile significantly. Rather than optimizing around giant all-reduce domains and synchronization-heavy GPU clusters, the system can optimize around memory locality, deterministic retrieval, low-overhead east-west communication, and integrated storage-compute fabrics operating directly over Ethernet.
This allows us to flatten the physical datacenter into a GPU-free, non-blocking, 1-tier full mesh architecture built around high-density CPU nodes and 51.2Tb silicon switching fabric. Storage and compute operate within the same physical domain rather than existing as separate backend and frontend systems. Ultra Ethernet principles such as packet spraying and dynamic load balancing are still valuable, but the objective changes fundamentally.
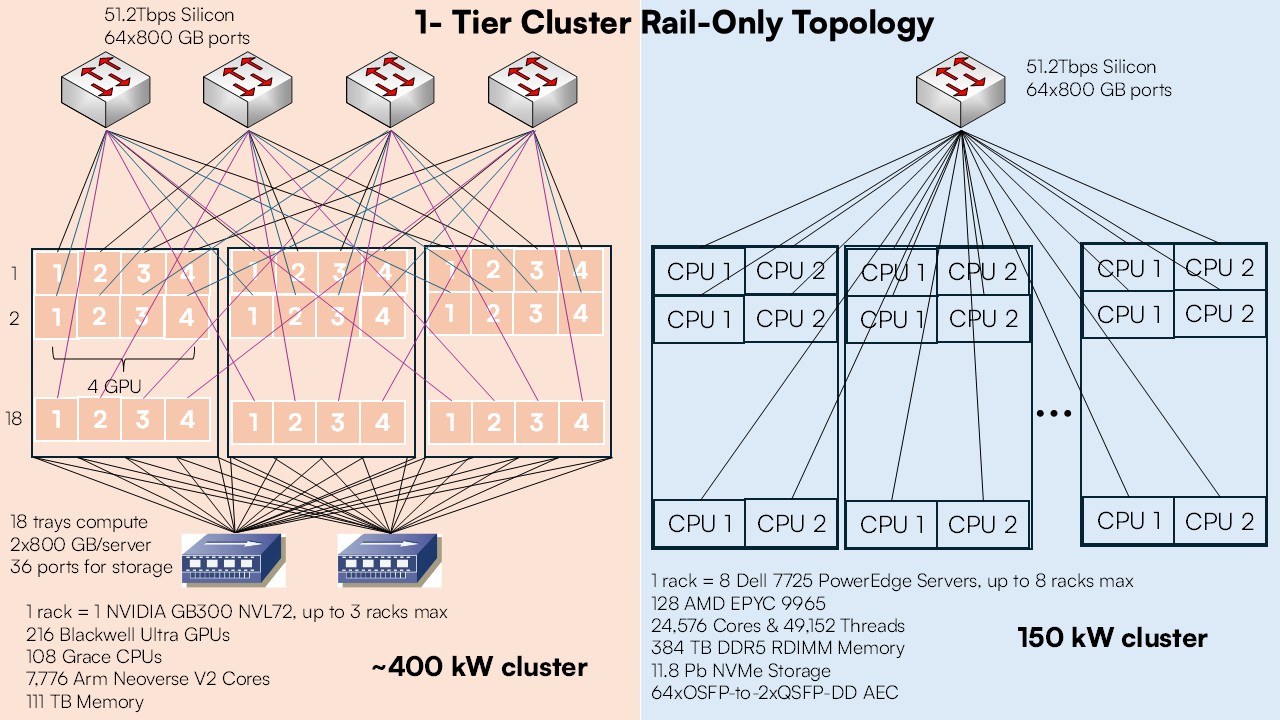 Figure 1: 1-Tier Rail-Only AI GPU Cluster vs ZERO GPU AI Cluster
Figure 1: 1-Tier Rail-Only AI GPU Cluster vs ZERO GPU AI Cluster
In a perfect world, GPU clusters should be 1-tier. Additionally for better scale-out, some researchers found that GPU traffic is mostly deterministic (GPU 1 of server x mostly talks to GPU 1 of other servers). We could then remove the spine in rail-optimized topologies and when GPU 1 of server A wants to send data to GPU 2 of server B, it will simply copy the data to GPU 2 on server A who will transmit it. Scale-up starts right at the chassis itself up to the entire rack.
Considering a 1-tier rail-only cluster and latest NVIDIA GPU generations, the limit of the tier is 216 Blackwell Ultra GPUs. While consuming more than twice our GPU-free cluster, this GPU cluster is insignificant for training capable LLM models (labs are using hundreds of thousands of GPUs to train models for months).
It's difficult to compare these two breeds of systems, as one is an LLM (training and inference) and the other is more a World Model (continual learning). But our 150-kW cluster can train a system from scratch to common sense (understanding of objects, making sense of the physical world, context awareness and the ability to learn anything from there.)
The goal is no longer maximizing throughput but minimizing retrieval latency.
The past several years of AI networking have largely been defined by one central challenge: how to scale synchronization between accelerators efficiently enough to keep increasingly large GPU clusters utilized.
The goal is no longer maximizing synchronized accelerator throughput across massive, distributed GPU fabrics.
It becomes minimizing retrieval and coordination latency across structured memory systems.
That distinction matters.
The next generation of AI infrastructure may ultimately depend on a different question: what happens when the architecture itself reduces the need for synchronization in the first place?
Almartis · May 2026